


Gemini 3 is insanely good at visual reasoning... and running a vending machine
Google’s stock is up maybe because Gemini 3 is good and its powered mostly by Google’s TPUs — or, maybe, because Alphabet’s about to launch a vending machine business.
How do you measure what an AI model can do?
You ask it to spell strawberry, make a video of Will Smith eating spaghetti, or do some basic math.
But, once you’ve exhausted all of the obvious tests, you might want something a little more formal — and it’s a question that researchers have been grappling with for years.
Now, there are a whole swath of benchmark tests that new AI models are put through, by both independent — and not so independent — organizations, in an increasingly weird kind of robot arena. Some of the tests are quizzes. Some require verbal, visual, or inductive reasoning. Many ask the large language models to do a lot of math that I cannot do. But one in particular asks a different question:
Vending-Bench 2, a test created by Andon Labs, puts LLMs through their paces by making them run “a simulated vending machine business over a year,” scoring them not on how many questions they got right out of 100, but how much cash was left in their virtual piggy banks at the end of the year.
This, it turns out, is hard for LLMs, which are prone to going off on tangents, losing focus, and are generally just quite poor at optimizing for long-term outcomes. That makes sense when you consider that the core of many of the AI models we use every day is, “What’s the most likely bit of text/pixel/image to come after this bit of text/pixel/image?”
Per Andon Labs, in the Vending-Bench 2 test:
“Models are tasked with making as much money as possible managing their vending business given a $500 starting balance. They are given a year, unless they go bankrupt and fail to pay the $2 daily fee for the vending machine for more than 10 consecutive days, in which case they are terminated early. Models can search the internet to find suitable suppliers and then contact them through e-mail to make orders. Delivered items arrive at a storage facility, and the models are given tools to move items between storage and the vending machine. Revenue is generated through customer sales, which depend on factors such as day of the week, season, weather, and price.”
Running the model for “a year” results in as many as 6,000 messages in total, and a model “averages 60-100 million tokens in output during a run,” according to Andon.
In the simulation, the AI model has to negotiate with suppliers as well as deal with costly refunds, delayed deliveries, bad weather, and price scammers.
Google’s Gemini 3 Pro, it turns out, is the best of any model tested yet — ending the year with $5,478 in its account, considerably more than Claude’s Sonnet 4.5, Grok 4, and GPT-5.1. That’s thanks to its relentless negotiating skills. Per Andon, “Gemini 3 Pro consistently knows what to expect from a wholesale supplier and keeps negotiating or searching for new suppliers until it finds a reasonable offer.”
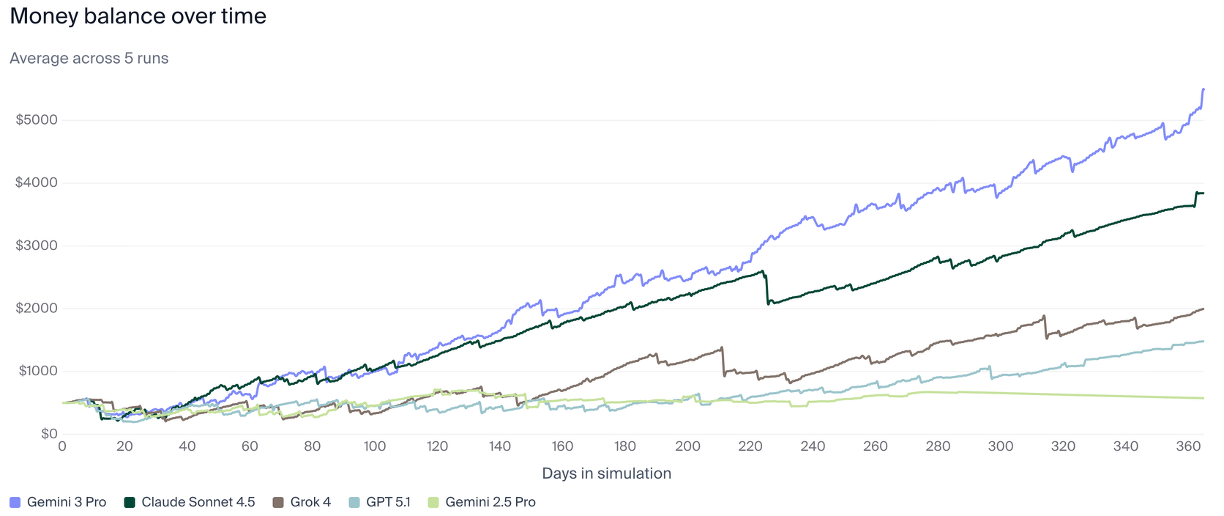
OpenAI’s model is, apparently, too trusting. Andon Labs hypothesizes that its relatively weak performance “comes down to GPT-5.1 having too much trust in its environment and its suppliers. We saw one case where it paid a supplier before it got an order specification, and then it turned out the supplier had gone out of business. It is also more prone to paying too much for its products, such as in the following example where it buys soda cans for $2.40 and energy drinks for $6.” Anyone who’s had ChatGPT sycophantically tell them they’re a genius for uttering even the most half-baked idea might understand how this can happen.
For what it’s worth, the $5,000 and change that Gemini averaged over its runs is considered pretty poor relative to what a smart human might be able to do, with Andon Labs estimating that a “good” strategy could make roughly $63,000 in a year.
What do you bench?
Diet Coke negotiations aside, Gemini’s scores on more traditional AI benchmarks were also impressive — at least, according to Google. A table posted on the company’s blog shows that Gemini 3 Pro tops or matches its peers in all but one of the benchmarks.
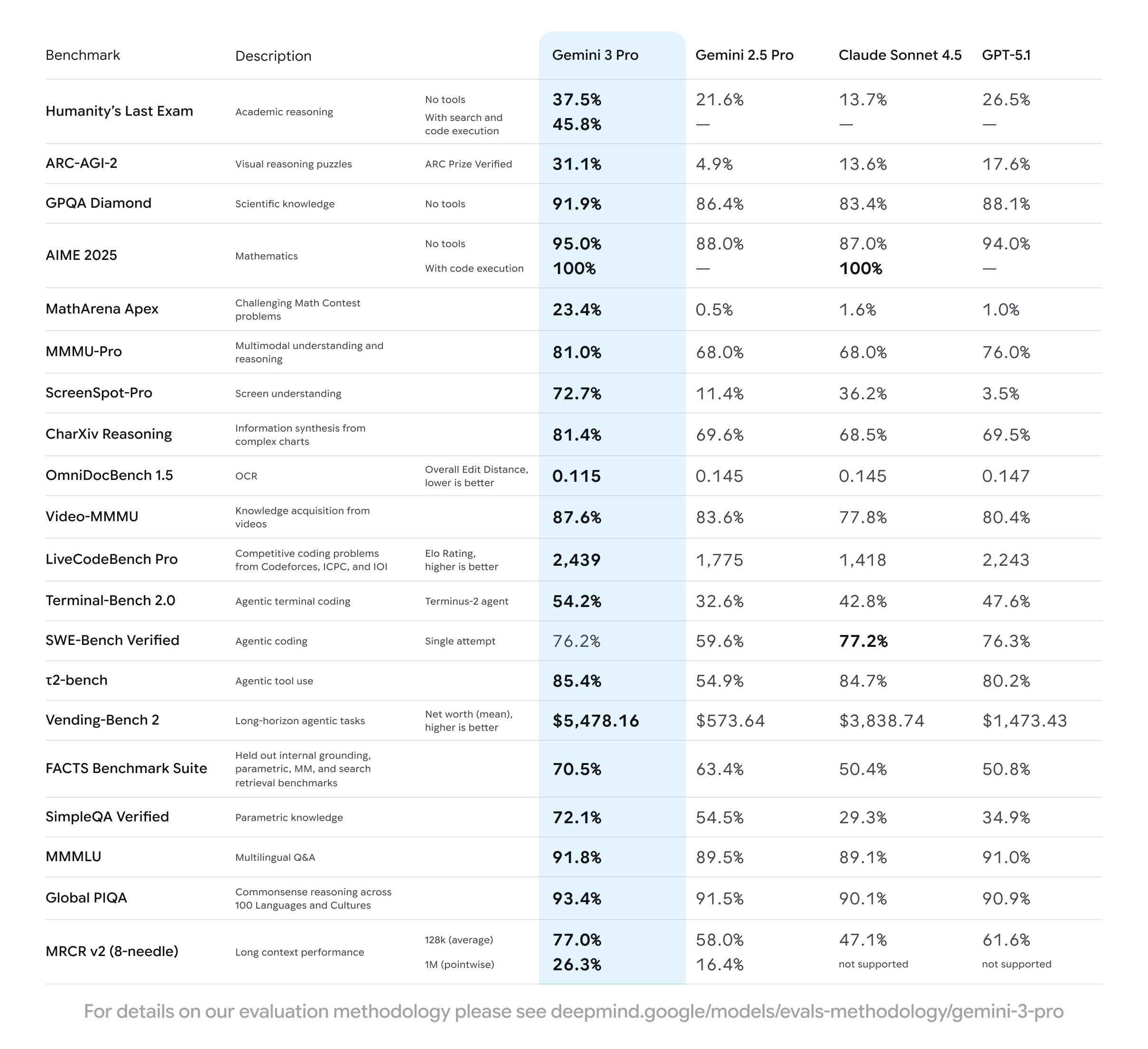
Its scores on visual reasoning tests — such as the ARC-AGI-2 test, where it scored 31.1%, way ahead of Anthropic’s and OpenAI’s best efforts — are particularly impressive. On ScreenSpot-Pro, a test that basically asks models to locate certain buttons or icons from a screenshot, Gemini 3 is leaps and bounds ahead of its rivals, scoring 72.7%. (GPT-5.1 scored just 3.5%.)
With Alphabet’s full tech stack responsible for the Gemini models, investor reaction to the release has been very positive so far, building on a wave of good news for the search giant this week. As my colleague Rani Molla wrote:
“[Gemini’s] performance is crucial to Google’s future success as the company embeds its AI models across its products and relies on them to generate new revenue from existing lines — particularly by driving growth in Cloud and reinforcing its ad and search dominance.”
Go Deeper: Check out Vending-Bench 2.





